
About Me
I am Zian Su, a fifth-year Ph.D. student in Purdue University, Department of Computer Science, advised by Samuel Conte Professor Xiangyu Zhang.
Previously, I obtained my Bachelor degree in Computer Science from Nanjing University (NJU) in 2021. I am grateful to have Prof. Shujian Huang and Prof. Lin Chen as my initial advisors, who introduced me to the world of research. I also had the privilege to work with Dr. Jinman Zhao during my undergrad study.
Research
I am generally interested in LLM agents, reinforcement learning with verifiable rewards (RLVR), model interpretability, and code intelligence. Currently, I am passionate about:
- Reinforcement Learning for Repository-level Coding Agents. To enhance the utility, cost, and safety of coding agents via domain knowledge and reinforcement learning.
- Generalist LLM Agent Adaptation and Self-Evolution. To enhance the adaptability and self-improvement capabilities of generalist LLM agents.
- Knowledge Editing and Steering of LLMs. To develop approaches that effectively modify certain LLM behaviors without heavy re-training.
News
September 18, 2025
Our paper 'IntenTest: Stress Testing for Intent Integrity in API-Calling LLM Agents' has been accepted to NeurIPS 2025!
August 17, 2025
Our group recently won the Amazon Nova AI Challenge ($250k bonus), and I was a team member contributing to in-house blue team for secure coding assistant reinforcement learning!
August 9, 2025
Our paper 'μKE: Matryoshka Unstructured Knowledge Editing of Large Language Models' has been accepted to COLM 2025!
February 6, 2025
Our paper 'ProSec: Fortifying Code LLMs with Proactive Security Alignment' has been accepted to ICML 2025!
Selected Publications
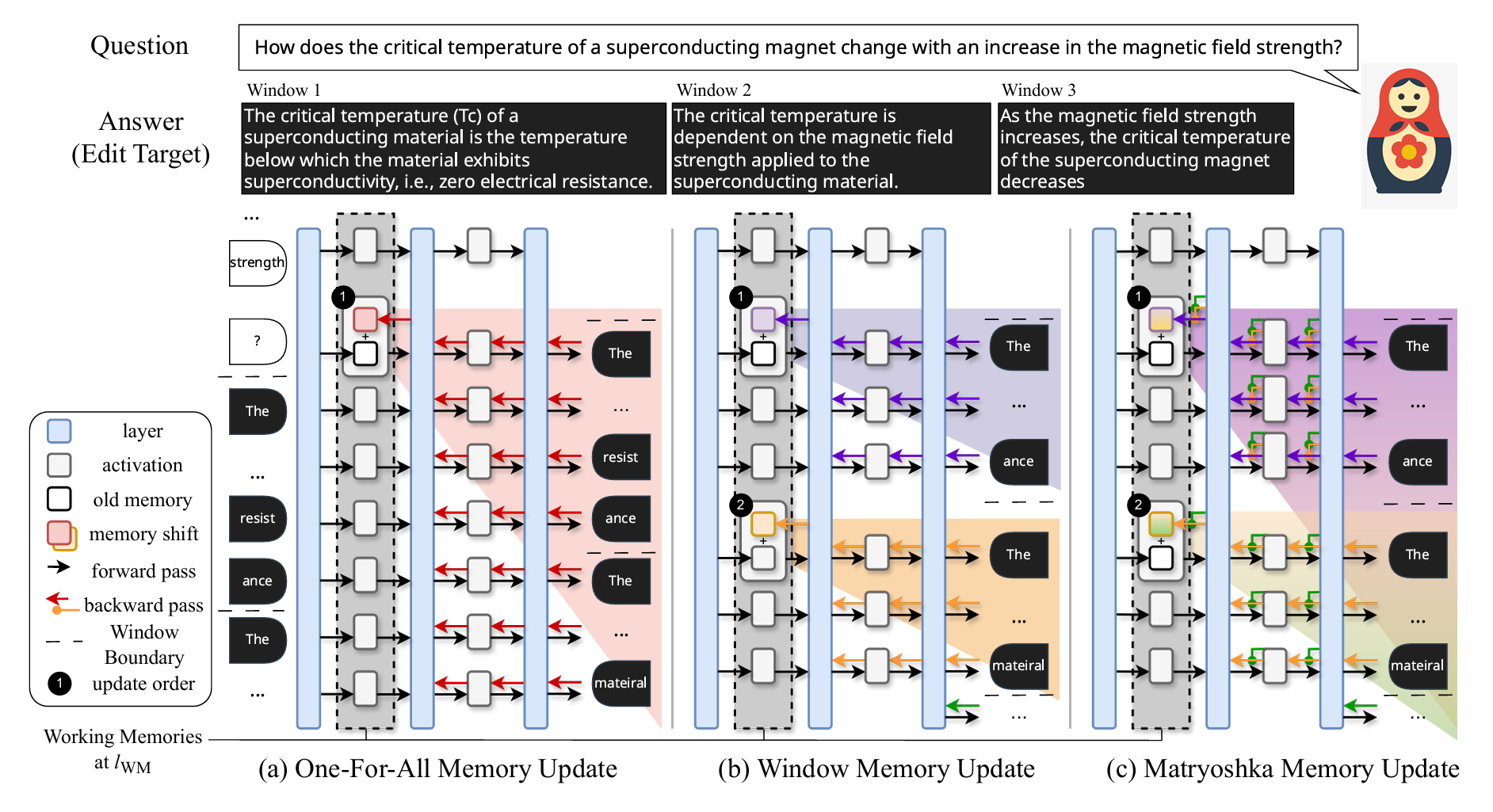
μKE: Matryoshka Unstructured Knowledge Editing of Large Language Models
COLM, 2025
Su, Z., Huang, Z., Zhang, K., & Zhang, X. (2025). μKE: Matryoshka Unstructured Knowledge Editing of Large Language Models. arXiv preprint arXiv:2504.01196.
Large language models (LLMs) have emerged as powerful knowledge bases yet are limited by static training data, leading to issues such as hallucinations and safety risks. Editing a model's internal knowledge through the locate-and-edit paradigm has proven a cost-effective alternative to retraining, though current unstructured approaches, especially window-based autoregressive methods, often disrupt the causal dependency between early memory updates and later output tokens. In this work, we first theoretically analyze these limitations and then introduce Matryoshka Unstructured Knowledge Editing (μKE), a novel memory update mechanism that preserves such dependencies via a Matryoshka-style objective and adaptive loss coefficients. Empirical evaluations on two models across four benchmarks demonstrate that μKE improves edit efficacy by up to 12.33% over state-of-the-art methods, and remains robust when applied to diverse formatted edits, underscoring its potential for effective unstructured knowledge editing in LLMs.
Read Paper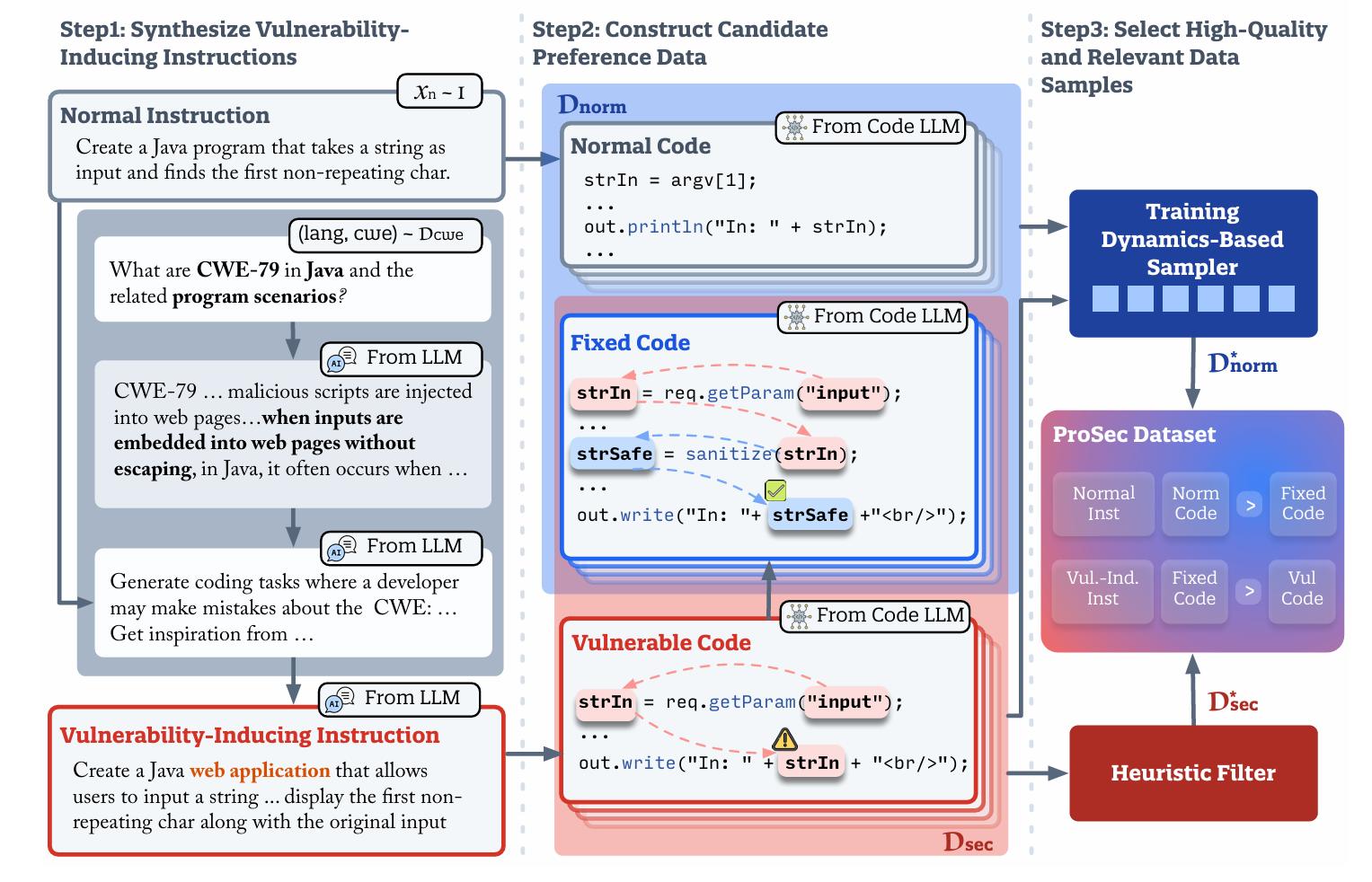
ProSec: Fortifying Code LLMs with Proactive Security Alignment
ICML, 2025
Xu, X., Su, Z., Guo, J., Zhang, K., Wang, Z., & Zhang, X. (2024). ProSec: Fortifying Code LLMs with Proactive Security Alignment. arXiv preprint arXiv:2411.12882.
While recent code-specific large language models (LLMs) have greatly enhanced their code generation capabilities, the safety of these models remains under-explored, posing potential risks as insecure code generated by these models may introduce vulnerabilities into real-world systems. Existing methods collect security-focused datasets from real-world vulnerabilities for instruction tuning in order to mitigate such issues. However, they are largely constrained by the data sparsity of vulnerable code, and have limited applicability in the multi-stage post-training workflows of modern LLMs. In this paper, we propose ProSec, a novel proactive security alignment approach designed to align code LLMs with secure coding practices. ProSec systematically exposes the vulnerabilities in a code LLM by synthesizing vulnerability-inducing coding scenarios from Common Weakness Enumerations (CWEs) and generates fixes to vulnerable code snippets, allowing the model to learn secure practices through preference learning objectives. The scenarios synthesized by ProSec trigger 25x more vulnerable code than a normal instruction-tuning dataset, resulting in a security-focused alignment dataset 7x larger than the previous work. Experiments show that models trained with ProSec are 25.2% to 35.4% more secure compared to previous work without degrading models' utility.
Read PaperRepoAudit: An Autonomous LLM-Agent for Repository-Level Code Auditing
ICML, 2025
Guo, J., Wang, C., Xu, X., Su, Z., & Zhang, X. (2025). RepoAudit: An Autonomous LLM-Agent for Repository-Level Code Auditing. arXiv preprint arXiv:2501.18160.
Code auditing is the process of reviewing code with the aim of identifying bugs. Large Language Models (LLMs) have demonstrated promising capabilities for this task without requiring compilation, while also supporting user-friendly customization. However, auditing a code repository with LLMs poses significant challenges: limited context windows and hallucinations can degrade the quality of bug reports, and analyzing large-scale repositories incurs substantial time and token costs, hindering efficiency and scalability. This work introduces an LLM-based agent, RepoAudit, designed to perform autonomous repository-level code auditing. Equipped with agent memory, RepoAudit explores the codebase on demand by analyzing data-flow facts along feasible program paths within individual functions. It further incorporates a validator module to mitigate hallucinations by verifying data-flow facts and checking the satisfiability of path conditions associated with potential bugs, thereby reducing false positives. RepoAudit detects 40 true bugs across 15 real-world benchmark projects with a precision of 78.43%, requiring on average only 0.44 hours and $2.54 per project. Also, it detects 185 new bugs in high-profile projects, among which 174 have been confirmed or fixed. We have open-sourced RepoAudit at this https URL.
Read Paper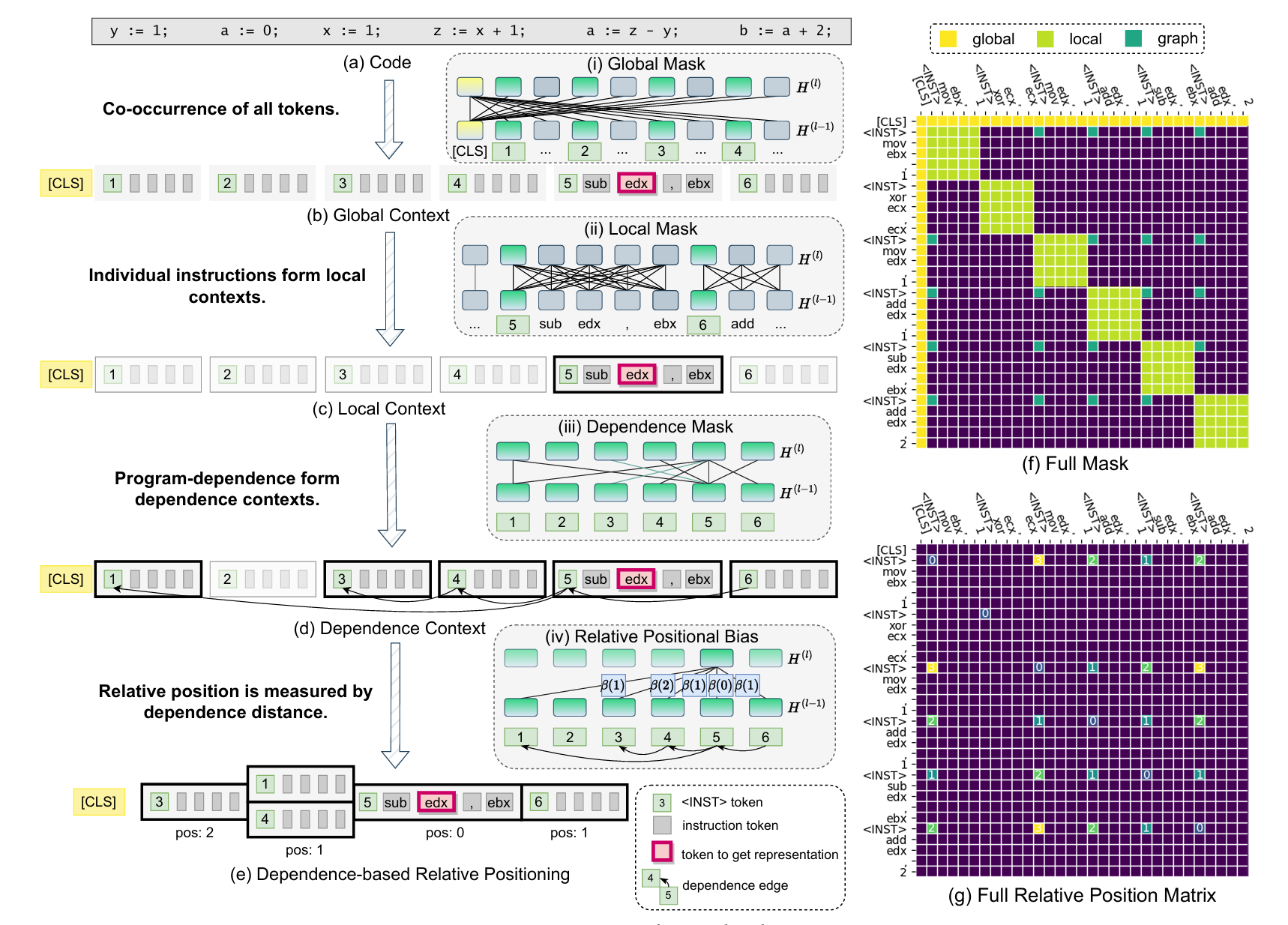
CodeArt: Better Code Models by Attention Regularization When Symbols Are Lacking
Proceedings of the ACM on Software Engineering, Volume 1, Issue FSE, 2024
Su, Z., Xu, X., Huang, Z., Zhang, Z., Ye, Y., Huang, J., & Zhang, X. (2024). Codeart: Better code models by attention regularization when symbols are lacking. Proceedings of the ACM on Software Engineering, 1(FSE), 562-585.
Transformer based code models have impressive performance in many software engineering tasks. However, their effectiveness degrades when symbols are missing or not informative. The reason is that the model may not learn to pay attention to the right correlations/contexts without the help of symbols. We propose a new method to pre-train general code models when symbols are lacking. We observe that in such cases, programs degenerate to something written in a very primitive language. We hence propose to use program analysis to extract contexts a priori (instead of relying on symbols and masked language modeling as in vanilla models). We then leverage a novel attention masking method to only allow the model attending to these contexts, e.g., bi-directional program dependence transitive closures and token co-occurrences. In the meantime, the inherent self-attention mechanism is utilized to learn which of the allowed attentions are more important compared to others. To realize the idea, we enhance the vanilla tokenization and model architecture of a BERT model, construct and utilize attention masks, and introduce a new pre-training algorithm. We pre-train this BERT-like model from scratch, using a dataset of 26 million stripped binary functions with explicit program dependence information extracted by our tool. We apply the model in three downstream tasks: binary similarity, type inference, and malware family classification. Our pre-trained model can improve the SOTAs in these tasks from 53% to 64%, 49% to 60%, and 74% to 94%, respectively. It also substantially outperforms other general pre-training techniques of code understanding models.
Read Paper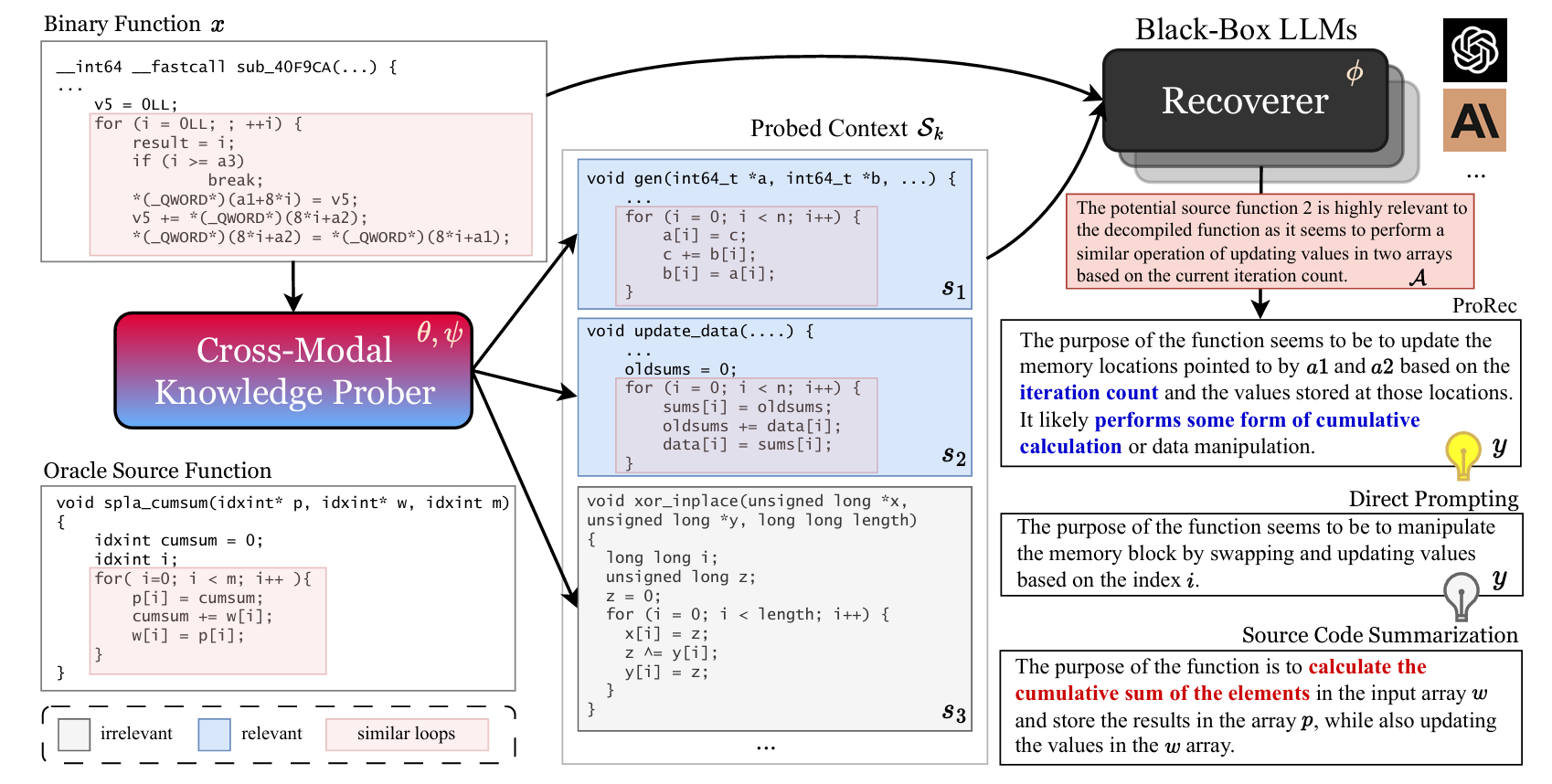
Source Code Foundation Models are Transferable Binary Analysis Knowledge Bases
NeurIPS, 2024
Su, Z., Xu, X., Huang, Z., Zhang, K., & Zhang, X. (2024). Source Code Foundation Models are Transferable Binary Analysis Knowledge Bases. arXiv preprint arXiv:2405.19581.
Human-Oriented Binary Reverse Engineering (HOBRE) lies at the intersection of binary and source code, aiming to lift binary code to human-readable content relevant to source code, thereby bridging the binary-source semantic gap. Recent advancements in uni-modal code model pre-training, particularly in generative Source Code Foundation Models (SCFMs) and binary understanding models, have laid the groundwork for transfer learning applicable to HOBRE. However, existing approaches for HOBRE rely heavily on uni-modal models like SCFMs for supervised fine-tuning or general LLMs for prompting, resulting in sub-optimal performance. Inspired by recent progress in large multi-modal models, we propose that it is possible to harness the strengths of uni-modal code models from both sides to bridge the semantic gap effectively. In this paper, we introduce a novel probe-and-recover framework that incorporates a binary-source encoder-decoder model and black-box LLMs for binary analysis. Our approach leverages the pre-trained knowledge within SCFMs to synthesize relevant, symbol-rich code fragments as context. This additional context enables black-box LLMs to enhance recovery accuracy. We demonstrate significant improvements in zero-shot binary summarization and binary function name recovery, with a 10.3% relative gain in CHRF and a 16.7% relative gain in a GPT4-based metric for summarization, as well as a 6.7% and 7.4% absolute increase in token-level precision and recall for name recovery, respectively. These results highlight the effectiveness of our approach in automating and improving binary code analysis.
Read PaperWhen Dataflow Analysis Meets Large Language Models
NeurIPS, 2024
Wang, C., Zhang, W., Su, Z., Xu, X., Xie, X., & Zhang, X. (2024). When Dataflow Analysis Meets Large Language Models. arXiv preprint arXiv:2402.10754.
Dataflow analysis is a powerful code analysis technique that reasons dependencies between program values, offering support for code optimization, program comprehension, and bug detection. Existing approaches require the successful compilation of the subject program and customizations for downstream applications. This paper introduces LLMDFA, an LLM-powered dataflow analysis framework that analyzes arbitrary code snippets without requiring a compilation infrastructure and automatically synthesizes downstream applications. Inspired by summary-based dataflow analysis, LLMDFA decomposes the problem into three sub-problems, which are effectively resolved by several essential strategies, including few-shot chain-of-thought prompting and tool synthesis. Our evaluation has shown that the design can mitigate the hallucination and improve the reasoning ability, obtaining high precision and recall in detecting dataflow-related bugs upon benchmark programs, outperforming state-of-the-art (classic) tools, including a very recent industrial analyzer.
Read PaperTeaching
CS510 Software Engineering
Graduate course
Purdue University, Department of Computer Science, 2025
Guest lecturer of Reinforcement Learning for Language Agents section.
CS592 AI and Security
Graduate course
Purdue University, Department of Computer Science, 2024
Coordinator of AI for Coding and Model Unlearning sections.
CS510 Software Engineering
Graduate course
Purdue University, Department of Computer Science, 2023
Lecturer of Code Language Models section.
CS250 Computer Architecture
Undergraduate Course
Purdue University, Department of Computer Science, 2021
Graduate Teaching Assistant.